In this article, I will lay out general ancestry trends of 150+ groups from the Indian subcontinent. And try to make it make sense to a lay audience.
Before I present the data table, there are some important caveats:
1. The purpose of the table is to concurrently compare the ancestry trends for 100+ groups of the Indian subcontinent. If the chosen sources are incorrect, they will be incorrect for all the groups but will still allow us to compare ancestry % across groups and make some conclusions. The fit (distance %) is not too relevant, and the distances of some groups will indeed be bad (>3%). However, that does not take away from our purpose of finding broad trends within the data.
2. These are informal distal models for modern groups of the Indian subcontinent. It is more likely than not that the actual sources of ancestry are different from the representative source groups chosen here. Eg. via formal qpAdm, Kangju Iranian group is chosen as the source of steppe ancestry for Kashmiri_Pandit and Telugu_Brahmin over Sintashta. As another example, a group having IVC ancestry does not mean that the ancestry is actually from IVC, it could come from any region of the country not yet sampled (which is 99% of the country) that has a similar ancestry profile as IVC.
3. I have used simulated AASI G25 coordinates to represent the indigenous Onge-like east Eurasian ancestry present in the South/East/Southeast of India. This coordinate has been calibrated to give an accurate % of Onge-like components for Southern tribal groups as per qpAdm output published in Narasimhan et al 2019. However, I am sure that this coordinate is not accurate, as is true with most simulated coordinates and should not be taken more literally than it is intended for the purpose of the below analysis.
4. It is almost certain that a single AASI coordinate cannot represent the various AASI populations that must have existed in different parts of India. However, for the purpose of our analysis, just one AASI will suffice.
5. The scaled coordinates of all groups were collected by a Greek-American Michael Mariopoulos. Samples are from published papers as well as self-submitted by users on online forums. I cannot vouch for their accuracy. Eg. some people are saying that most of the Rajput samples cannot be verified to be from Rajputs. Moreover, the process of creating coordinates from raw data or eigenstrat/plink format data and references used may or may not be biased in some unknown manner. That being said, the overall results do make some sort of sense.
The Sources
1. IVC_lowAASI - Sample id I8726 from Shahr-Sokhta. 11% Onge (AASI) ancestry via qpAdm.
2. IVC_highAASI - Sample id I8728 from Shahr-Sokhta. 39% Onge (AASI) ancestry via qpAdm.
3. AASI - Simulated AASI coordinates
4. Lao_BA - Bronze age sample from Laos to check Austroasiatic language connection
5. Mongolia_N - Mongol neolithic ancestry to check for Mongol connection
6. Npl_Chokhopani - Nepali ancient sample to check for Tibetan/East Asian ancestry
7. Sintashta - Steppe_Mlba samples to check for steppe ancestry
8. Sarazm - SC Asian Eneolithic samples (some populations like Kalasha need it as per qpAdm).
9. Wezmeh_N - West Iranian neolithic ancestry
10. BMAC_Gonur - Bactrian bronze age ancestry (2100BCE from Gonur, Turkmenistan).
The Regions
Groups have been marked to be from North India, West India, South India, East India, NE India, Nepal/Tibet, Pakistan & Afghanistan. If there are obvious errors, please mention them in the comments.
Language Groups
Groups have been marked to speak one of several language families - Austroasiatic (Munda), Tibeto-Burmese, Dravidian, Iranian (NW, Eastern, & Western), Indo-Aryan, and isolates (Kusunda & Burusho). If there are obvious errors, please mention them in the comments.
Method
I am going to try and correlate language groups with specific sources, I will use correlation = causation logic for most of the language groups, although it runs a significant risk of 'correlation is causation fallacy'. I will not challenge commenters who point out this fallacy, but you see that for most of them the inference turns out to be sound.
I will start by explaining the easiest groups first, and then remove those groups for the next language families one by one. For the statistical test, I will use Welch's T-Test of unequal variances and sample sizes to test that hypothesis of equal means of a particular ancestry within 2 sets of groups.
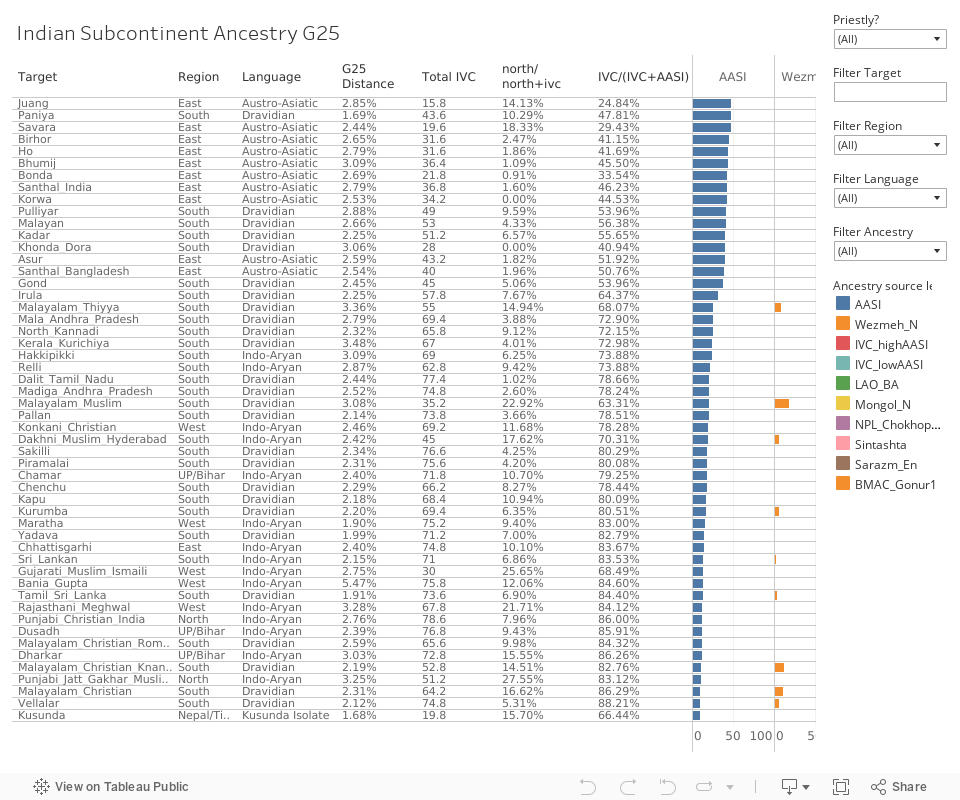
Dashboard containing All Groups
You can play around with this dashboard. Laptop/PC/Tablet will allow better ease of use. Use it in fullscreen mode for full view (bottom right). Use the filters on the right to filter by Group name, Language, or region. You can sort columns in descending or ascending order. If you are on phone, you should skip ahead and come back to this dashboard on a PC, it may be good fun.
Mongol Neolithic Ancestry
Of the 158 groups sorted by Mongol_N ancestry, 2 groups stand out. The Hazaras of Pakistan and Afghanistan are Turko-Mongolic descendants but who have become Persianized in language with time. These 2 groups possess ~26% Mongol_N-related ancestry. Some Hazaras from Herat still supposedly speak Moghol Mongolic language, although it is highly endangered. We can directly tie their Mongolic ancestry to their Moghol language (although most speak the Hazaragi dialect of Dari today). No other group in our list speaks Mongolic languages, and neither do they have significant Mongol ancestry.
Tibetan Related Ancestry
The next language group which is easiest to explain is the Tibeto-Burmese group. All the TB groups from Nepal, Tibet and NE India have a high Chokhopani-related ancestry. This ancestry can be considered causal to their languages. I won't be doing any statistical tests as the difference between TB and Non-TB is clear enough. There are no TB groups which lack this ancestry.
Baltis are one of the few Tibeto-Burmese speaking groups in Pakistan and they show 26% Chokhopani-related ancestry. This ancestry is absent in other non-TB groups of Pakistan and therefore is additional evidence for the relation of TB with Tibetan ancestry.
In Nepal, Khas Chhetri and Tharu are Indo-Aryan speakers who also have significant Chokhopani-related ancestry, but unlike other Nepalis and NE Indians, they have additional IVC-related ancestry (25-45%) and steppe-related ancestry (4-15%) which explains their languages.
Kusunda is a language isolate found in Nepal with speakers who also have a high Chokhopani-related ancestry. Experts believe that it is not a part of the Sino-Tibetan macrofamily. Isolates can seldom be explained away by ancestry components, so their presence remains a mystery. It is likely that it has a very old presence in the region, and managed to survive thus far due to isolation.
SE Asian Laos_BA-related Ancestry
Arranging the remaining groups by descending order of Laos_BA ancestry, we see that the Austroasiatic (Munda) tribal groups come out at the top. Statistically, using the Welch T-Test, the 10 Munda groups have a mean of 22% Laos_BA ancestry as compared to the other 126 groups with 0.7% avg Laos_BA ancestry. The difference in the mean is statistically significant with p-value p=5.581e-7 and a large effect size of 6.45. The SE Asian ancestry peaks in the Bonda at 32%. There are no Munda speakers who lack this ancestry.
Konda Dora group from Andhra Pradesh is an outlier as they still speak Dravidian despite 31% SE Asian ancestry. This can be attributed to them assimilating with other Dravidian neighbours over time.
BMAC Ancestry
From the remaining groups, I sort the table by descending BMAC ancestry. The Eastern Iranian-speaking Pashtuns come up to the top. To test whether the relationship between BMAC and eastern Iranian languages is statistically significant, I choose to compare only with remaining groups from Afghanistan, Pakistan, and North and West India.
The mean of BMAC ancestry in the 9 Pashtun groups and the other 54 groups from the NW part of the Indian subcontinent is 42% and 14% respectively. The means are statistically unequal with a p-value of 2.519e-7, and the effect size is 'large' at 2.95.
West Iranian Wezmeh_N ancestry
After arranging the remaining groups by descending order of Wezmeh_N ancestry, 4 groups with high Wezmeh_N ancestry can be seen at the top. Of these, 3 groups - 2 Balochi and Makrani speak NorthWest Iranian dialects of the Iranian language family. The Baloch & Makrani have >48% Wezmeh_N ancestry which explains their NW Iranian languages.
The 4th group, Brahui, is an outlier and they are considered to speak a Dravidian language of the Kurux-Malto branch (East India). Brahui people intermarry with the Balochi; their vocabulary consists of about 15-20% Dravidian words, the rest being Balochi. Genetically, Brahui cannot be distinguished from Balochi.
Krishnamurthy, Elfenbein and Witzel were proponents of Brahui being a recent entrant from the east. The reasoning is
1. Lack of older loanwords from Avestan or Pashto, only from symbiotic Balochi (Elfenbein 1987, Witzel 1999). Balochi itself is a later entrant (post 700CE) into the region. This can be verified by their own oral history, language dialect as well as genes.
2. Brahui possess shared innovations with Kurux/Malto, of which *v>b is one, likely under Magadhan influence in their proto period (Krishnamurthy 2003, Elfenbein 1987). IA neighbours of Brahui which are Western Indo Aryan- Sindhi, Lahnda, Jatki did not undergo *v>b unlike Eastern Indo Aryan and Kurux/Malto Dravidian branch under the influence of eastern Indo Aryan. (Krishnamurthy 2003).
One reason given by proponents of Brahui being a local Dravidian language of great antiquity is that there is no excess Dravidian ancestry in Brahui as compared to the Balochi, and therefore they cannot be late migrants into the region. I must tell them that this argument works both ways. Balochi people are known to be post-700CE migrants from western Iran. If that is so, and if Brahui were locals in modern Baluchistan when west Iranians came, then why do Balochi not possess excess West Iranian ancestry to the exclusion of the Brahui? The answer is simple, Brahui and Balochi intermarry freely and more than 2/3rd Brahuis also speak Balochi. Any genetic differentiation between them has been lost.
Iranicaonline has more information about Brahui.
Finally, we are left with 113 Indo-Aryan and Dravidian Groups
Explaining the other groups was easy. I shall analyze these 113 using various metrics, as it pertains to the centuries-old question of the origin of Indo-Aryan and Dravidian languages.
By AASI Ancestry
 |
| AASI descending order |
 |
| AASI ascending order |
We can see that by descending order of AASI, the southern Dravidian groups cluster at the top. By ascending order of AASI, the north Indian Indo-Aryan groups cluster at the top. The middle is a mix of Indo-Aryan and Dravidian speakers.
For 74 Indo-Aryan and 39 Dravidian groups, the mean of AASI ancestry is 5.4% and 18% respectively. This difference is statistically significant with a p-value of 4.043e-7.
This means that Dravidian languages are correlated with higher AASI ancestry.
By Total IVC Ancestry
Total IVC ancestry is defined as IVC_lowAASI + IVC_highAASI.
Welch T Test says that the mean of Total IVC ancestry in Dravidian speakers at 64% is significantly more than that of Indo-Aryan speakers at 57%, with a p-value of 0.0056 and a medium effect size of 0.54.
However, there are problems with this measure because the absolute IVC ancestry is reduced in the north due to later Sintashta ancestry (addressed later) but not in the south. For eg 38% of IVC ancestry is taken away from Rors due to Sintashta. So we must control for Sintashta ancestry in some manner. Another reason to doubt that this metric is valid for language comparisons is that AASI is also significantly related to Dravidian languages.
By IVC/(IVC+AASI) ratio
To control for Sintashta ancestry (and BMAC/Sarazm as well among others), we use the Total IVC / (Total IVC + AASI) ratio. This ratio tells us the local ancestry profile of various groups before they were impacted by various external ancestries. Intuitively, you could think of this ratio as depicting how northern or southern/SouthEastern each group is.
 |
| Descending order of IVC/(IVC + AASI) ratio |
The mean ratio for Indo-Aryan groups is 92% and that for Dravidian groups is 78%, statistically significant with a p-value of 0.000001935. The effect size is deemed large at 1.23.
Interestingly, filtering only for Dravidian speakers, the southern groups with the highest IVC ratio can be seen here.
The ones at the top are Brahmin_Nambudiri, Nairs, Brahmin_TN, Vaniya_Chettiar (Trader), Brahmin_Andhra, Brahmin_TN, Nasrani (Syriac) Christian Malayali, Kamma, Telugu, Reddy, Velama, Vellalar, Brahmin Kannadiga, etc. Notice that all these groups are either Brahmins or forward/dominant castes of the region. The IVC ratios betray their ultimately northern origin. The almost equal measure of sintashta and BMAC ancestry tell us that the admixture was probably from Iranic - like groups (TKM_IA or Kangju).
It should come as no surprise that Dravidian Brahmins are migrants from the north, and their ancestry tells us that the mixing with AASI-heavy groups of the south has been minimal. But what explains the heavy IVC ancestry of the other forward groups like the Velama, Kamma, Vellalar, Nair etc.?
At least some of them have recorded northern origins, which is borne out by the above data. For example, the Vellalars of Tamil Nadu as said to be descendants of Sri Krishna from Dwarka Gujarat, as recorded in ~100BCE Tamil Sangam poetry. The same sources also tell us that the Velallars of that time (Sangam era) were the 49th generation in the line of the king of Dwarka (Sri Krishna). (VJ Tambipillai, 1908).
In Tamil Nadu, a BRW potsherd from the 1st century CE has the name Yadu BalAbhooti (Immense strength?) written in Prakrit Brahmi, confirming the Yaduvanshi/Dwarka links. (
source)
Similarly, Kammas and Velamas also have a northern origin story. Some origin stories of the Telugu Kammas are listed
here.
Notice that all the Dravidian SC and Tribal groups cluster at the bottom.
By Sintashta Ancestry
Absolute Sintashta-related ancestry is more significantly correlated with Indo Aryans of the north than Dravidian speakers of the south with a P-value of 5.922e-14, mean of 18.8% vs 7.8% respectively.
Jatts/Rors from Haryana, Punjab and Western UP cluster at the top. Followed by Brahmins and then by other groups, generally speaking. Bengali, Gujarati, and Brahmins from the south fall quite low in this list compared to Punjabis, Haryanvis and Western UPites.
A more enlightening metric may be the ratio of (Sintashta + SC Asia )/ (Sintashta + SC Asia + IVC). This controls for AASI and other ancestries. A similar metric was used by Narasimhan et al 2019 to prove that UP/Bihar Brahmins had a significantly higher ratio of this metric.
Priestly vs non-Priestly by Ratio of Sintashta/Local Northern ancestry
I define this ratio as Sintashta/(Sintashta+IVC+BMAC+Sarazm). We shall look at multiple regions separately - Pakistan/North/West, UP/Bihar, East & South to see Priestly vs non-priestly trends.
We shall do this region-wise to test whether the steppe ancestor is correlated with Priestly groups vs other groups of the same region.
North/Pakistan/West
 |
| Steppe ratio in descending order |
The mean of the 5 Brahmin groups in these regions is 22.22%, and that of the other 42 non-priestly groups is 21.9%. The hypothesis that the means of the 2 sets are the same cannot be rejected, with a p-value of 0.8044.
UP/Bihar/Nepal
 |
| Steppe ratio in descending order |
The mean of the 4 Brahmin groups of this region is 25.9% and that of 13 non-priestly groups is 19.75%.
The hypothesis that the means are equal cannot be rejected, p-value = 0.07548.
East and North East
 |
| Steppe ratio in descending order |
Only focussing on the Indo-Aryan groups and Brahmins of East and NE, the mean of Brahmins is 20% and that of non-Priestly groups is 16%. The hypothesis of equal means cannot be rejected, with a p-value of 0.444.
South
 |
| Steppe ratio: Groups from South in descending order |
The difference in mean of the steppe ratio is significant at 18% and 8% with a p-value of 0.0009749. This is expected as the Brahmins of the south are originally from the north and the SC/ST Dravidian-speaking groups of the south have very low steppe admixture.
The results of this section refute the claim made by Narasimhan et al that Sintashta has a causal relationship with the priestly groups. That claim is only tenable for Southern India, and even there it is not clear whether the causal ancestry is the IVC one or the steppe one.
DISCUSSION & CONCLUSION
After assigning the roles of SE Asian, Tibetan, Mongol, West Iranian & BMAC ancestries in the Indian subcontinent, we are left with these options to consider.
1. IVC was Indo-Aryan, AASI spoke Dravidian and steppe ancestry represents an unknown language / later Iranian contact.
The evidence in favour of this option is
a) IVC ratio is significantly correlated with Indo Aryan languages.
b) Absolute AASI % and AASI/IVC ratio are both significantly associated with Dravidian languages
c) Higher steppe ratio is not significantly associated with priestly castes in NW, UP/Bihar/Nepal or East India.
2. Steppe brought Indo-Aryan, AASI spoke Dravidian and that IVC languages were unknown/Dravidian and got lost with Indo-Aryan introduction.
The evidence in favour of this option is
a) Absolute steppe ancestry is significantly correlated with Indo Aryan languages.
b) Absolute AASI % and AASI/IVC ratio are both significantly associated with Dravidian languages
3. Steppe brought Indo-Aryan, IVC spoke Dravidian and AASI languages were unknown.
The evidence in favour of this option is
a) Absolute steppe ancestry is significantly correlated with Indo Aryan languages.
b) Absolute IVC ancestry is correlated with Dravidian languages (logical issue with the mathematics here as steppe ancestry takes away a lot of IVC ancestry in the north where AASI is close to nil anyway)
A firm counter against this option is that AASI as well as AASI/IVC ratio is very strongly linked to Dravidian languages, whereas both the IVC ratio and steppe ratio are not.
Probably the most important question is of Sanskritization of the Dravidian languages, the introduction of Vedic culture to the South, the introduction of Sinhalese to Sri Lanka, and the curious case of the Vaghri Boli Indo-Aryan speakers of Karnataka & TN - Hakkipikki and Narikurava. Sinhalese is said to be (at least partially) descended from Magadhan Prakrit which likely reached Sri Lanka during Mauryan times, although I am not sure if this is the consensus view.
It is a fact that the forward castes of South India have a much more northern profile in terms of their IVC ancestry, so the idea that they were elites who dominated and assimilated into the local culture of the south while at the same time introducing Vedic culture and patronizing Brahmins from the north cannot be discounted. The earliest kings of the south, the Cheras, Cholas and Pandyas all claimed to be of Kshatriya origin from the north. Similar to Vellalars, the Hoysalas and Chalukyas are also said to be of Yaduvanshi descent (Tambipillai 1908). Given that all of these kingdoms were steeped in Vedic culture, it is likely that these elites brought the wave of Sanskritization and Vedic culture to the Dravidian south.
To conclude, modern data from various groups of the Indian subcontinent do not provide sufficient evidence to prove which ancestry (IVC or steppe) is responsible for Indo-Aryan languages.
Also, Read









80 comments:
Hey Ashish,
Just a little quibble. You have marked Yadava as Indo-Aryan and from UP/Bihar however, these Yadava samples are from south if I remember correctly. I don't remember the paper at the moment, was probably from Metspalu's !(Castes like Golla, Konar etc. in south have adopted 'Yadava' title). You can check Narasimhan's supplement for difference between the two(I know his modelling had issues for many pops but still) where he had east UP Yadav/Ahir samples and Tamil Yadava samples, and east UP Yadav were much more steppe shifted than Tamil Yadava.
Now regarding using the IVC/(IVC+AASI) ratio, my question is - Was the population that brought Sintastha ancestry to the northern Indian plains unadmixed ? For the time being let's assume the mainstream AMT scenario ,so by the time Sintastha folks reached the Punjab plains, they must have mixed with some other ancestry en route including some IVC ancestry. Wouldn't that mean that when computing IVC/(IVC+AASI) ratio, one would have to theoretically substract the IVC% coming from the Steppe_MLBA carrying vector ?
I will check the Yadava case.
Wrt steppe ratio, there were 2 calculations i considered
1. Steppe/(steppe+ bmac+sarazm+ivc total)
2. (Steppe + bmac + sarazm)/(steppe+bmac+sarazm+ivc)
The second one has the problem that it assumes that all of the bmac/sarazm came along with steppe ancestry which is not the case for NW groups (see swat for example), aligrama IA has bmac but no steppe.
First one also has a problem because at least is some groups steppe did come with bmac ancestry. But using this feels preferable as I am still checking for 'only steppe' impact across all groups.
Yes, these Yadava are from Vizag, changed it in the dashboard.
There are many isolate languages in the region - Vedda, Nihali, Kusunda, Burushko etc and there are also substrates from "dead languages" proposed by some linguists too. Overall, we are looking at some 8 to 11 language isolates proposed in linguistic studies for the region, some dead and some living.
It would not be easy to associate languages with aDNA when we consider such isolate language examples.
Thats fine. Americas were populated from the same source population. But they have incredible language diversity. From wiki
"Northern America
There are approximately 296 spoken (or formerly spoken) Indigenous languages north of Mexico, 269 of which are grouped into 29 families (the remaining 27 languages are either isolates or unclassified).[citation needed]"
Check this
https://en.wikipedia.org/wiki/Category:Language_isolates_of_North_America
In Nepal, Khas Chhetri and Tharu are Indo-Aryan speakers who also have significant Chokhopani-related ancestry, but unlike other Nepalis and NE Indians, they have additional IVC-related ancestry (25-45%) and steppe-related ancestry (4-15%) which explains their languages.
Steppe has nothing to do with that nor with PIE
Thats why you can find these NON-steppe lineages with them: Haplogroup J2a-M410(xM68, M47, M67, M158) (9.9%), Haplogroup J2b2-M12/M102/M241(xM99) (4.1%), Haplogroup E-M35 (1.8%)
"Steppe has nothing to do with that nor with PIE"
I don't disagree
You definitely are a moron Vashishta, firstly modelling Baloch with Neolithic sources when essentially their origins are from Southern Balochistan , which would correspond with Kulli , in other words they descend from a population which is heavy with Iran_N + low AASI beyond 8726 , and on qpAdm Pashtuns and Baloch need Western Iranian ancestry. Modern day Indians and even many of those Punjabi need some South Indian tribal source, using super Iran_N rich samples to show some pattern with them being Indo Aryan speakers shows your epic stupidity. Get over it even your Goojratis were conquered by Horse people, its pretty evident below. David is right your a delusional retard. Stick to scamming elderly Americans
sample: Brahmin Gujarat:Average
distance: 0.8389
Tamil_GBR: 59.2
Srubnaya_Alakul_MLBA: 20.4
Dzharkutan1_BA: 19.8
Gonur1_BA: 0.6
Sintashta_MLBA: 0
Brahmin Gujarat:Average
distance: 0.6340297340000001
Telugu_GBR: 58.4
Dzharkutan1_BA: 20.4
Srubnaya_Alakul_MLBA: 19
Tarim_EMBA1: 2.2
Gonur2_BA: 0
sample: Brahmin Gujarat:Average
distance: 0.98162
Telugu_GBR: 56.2
Otyrar_Antiquity: 22.6
Abusanteer_IA3: 21.2
@bluecaviar
1. Read the caveats, this is not supposed to be a best fit modeling for each individual group, rather a broad sweep distal modeling to compare each group based on the same sources.
2. Baloch, brahui, Makrani cannot be modeled without additional wezmeh_n, iranN ancestry when you attempt best fits. On G25. QpAdm is another matter, I haven't tried it
3. You are suggesting that brahmin_gujarat are admixed with an iranic population with 20% steppe and 20% bmac ancestry . So something like tkm_ia (50/50 steppe bmac). I must say, I don't particularly disagree. Only issue is that an iranic population cannot give birth to sanskritic languages.
To cement your stupidity further, you again go on to prove the iranic admixture by modeling Gujarati Brahmins with otyrar (east iranic sogdian speaking Kangju) and abusanteer (Xinjiang, again iranic).
For quite a long time I have argued that steppe admixture in many indians is from a later post Vedic iranic source. So thank you for making my points for me.
Wrt 'scamming elderly americans' go post your racist rants on stormfront.
@rottencaviar
"You definitely are a moron Vashishta, firstly modelling Baloch with Neolithic sources when essentially their origins are from Southern Balochistan , which would correspond with Kulli , in other words they descend from a population which is heavy with Iran_N + low AASI beyond 8726 "
This is not true. These pops need AASI heavy ancestry for sure. Check out Saidu_o requirement. Go weep.
Target: Makrani (all scaled averages, 4x runs on vahaduo)
Distance: 2.3683% / 0.02368256
48.6 IRN_Wezmeh_N
12.6 PAK_Saidu_Sharif_H_o
12.2 IRN_DinkhaTepe_BIA_A
8.8 RUS_Sintashta_MLBA
7.4 UKR_Srubnaya_MLBA
5.6 KAZ_Shoendykol_MLBA_Fedorovo
4.0 IRN_Shahr_I_Sokhta_BA2
0.8 NPL_Chokhopani_2700BP
0.0 ARM_Agarak_MA
0.0 ARM_Aghitu_Anc
0.0 ARM_Aknashen_N
0.0 ARM_Areni_C
0.0 ARM_Bagheri_Tchala_EIA
0.0 ARM_Black_Fortress_LBA
0.0 ARM_Bover_EIA
0.0 ARM_Bover_Urartian
0.0 ARM_Bragdzor_EIA
0.0 ARM_Brardzryal_Urartian
0.0 ARM_Dzori_Gekh_LBA
0.0 ARM_Harjis_LateUrartian
0.0 ARM_Karashamb_EIA
0.0 ARM_Karashamb_LBA
0.0 ARM_Karmir_Blur_Anc
0.0 ARM_Karmir_Blur_EIA
0.0 ARM_Karmir_Blur_Urartian
0.0 ARM_Karmir_Blur_Urartian_o
0.0 ARM_Karnut_EIA
0.0 ARM_Keti_Anc
0.0 ARM_Keti_EIA
0.0 ARM_Keti_LBA
0.0 ARM_Keti_Urartian
0.0 ARM_LBA
0.0 ARM_Lchashen_LBA
0.0 ARM_Lori_Berd_LateUrartian_A
0.0 ARM_Lori_Berd_LBA
0.0 ARM_Masis_Blur_N
0.0 ARM_MBA
0.0 ARM_Nerkin_Getashen_LBA
0.0 ARM_Noratus_Anc
0.0 ARM_Noratus_EIA
0.0 ARM_Noratus_LBA
0.0 ARM_Pijut_LBA
0.0 ARM_Pijut_Urartian
0.0 ARM_Pijut_UrartianPeriod
0.0 ARM_Sarukhan_Anc
0.0 ARM_Sarukhan_EIA
0.0 ARM_Sarukhan_LBA
0.0 ARM_Sarukhan_unknown
0.0 ARM_Talin_KuraAraxes_EBA
0.0 ARM_Tavshut_Trialeti_MBA
0.0 ARM_Tekhut_LBA
0.0 ARM_Yerevan2_unknown
0.0 IRN_DinkhaTepe_BIA_B
0.0 IRN_Ganj_Dareh_Historic
0.0 IRN_Ganj_Dareh_N
0.0 IRN_Hajji_Firuz_C
0.0 IRN_Hajji_Firuz_IA
0.0 IRN_HajjiFiruz_BA
0.0 IRN_Hasanlu_IA
0.0 IRN_Hasanlu_LBA_A
0.0 IRN_Hasanlu_LBA_B
0.0 IRN_Hasanlu_MBA
0.0 IRN_Shahr_I_Sokhta_BA1
0.0 IRN_Tepe_Hissar_C
0.0 IRN_TepeHissar_C
0.0 KAZ_Dali_EBA
0.0 KAZ_Dali_MLBA
0.0 KAZ_Kangju
0.0 KAZ_Saka_TianShan_IA
0.0 Kura-Araxes_ARM_Berkaber
0.0 Kura-Araxes_ARM_Kalavan
0.0 Kura-Araxes_ARM_Kaps
0.0 Kura-Araxes_ARM_Karnut
0.0 Kura-Araxes_ARM_Talin
0.0 MDA_Catacomb_Dănceni_MBA
0.0 MDA_Catacomb_MBA
0.0 MNG_North_N
0.0 PAK_Loebanr_IA
0.0 PAK_Loebanr_IA_o
0.0 PAK_Saidu_Sharif_H
0.0 RUS_Catacomb
0.0 RUS_Srubnaya_Alakul_MLBA
0.0 RUS_Srubnaya_MLBA
0.0 RUS_Srubnaya_MLBA_o
0.0 Saka_Kazakh_steppe
0.0 Saka_Kazakh_steppe_o1
0.0 Saka_Kazakh_steppe_o2
0.0 Saka_Tian_Shan
0.0 Saka_Tian_Shan_o
0.0 TJK_Ksirov_H_Kushan
0.0 TJK_Sarazm_En
0.0 TKM_Geoksyur_En
0.0 TKM_Geoksyur_N
0.0 TKM_Gonur1_BA
0.0 TKM_Gonur1_BA_o
0.0 TKM_IA
0.0 TUR_E_Van_BIA_pre-Urartian
0.0 TUR_E_Van_Urartian
0.0 TUR_E_Van_Urartian_o
0.0 UKR_Catacomb
0.0 USA_San_Catalina_Island
0.0 UZB_Sappali_Tepe_BA
0.0 UZB_Sappali_Tepe_BA_o
0.0 UZB_Sappali_Tepe2_BA
Your a confirmed Moron, do you really think Indian tribal populations are on the borderlands of the Eastern Iranian periphery/Balochistan? Than you need an atlas and history book for the region. Ah yes play the race card when you have no other logical arguments. Boo hoo.
sample: Balochi:Average
distance: 1.91074519
IA_Rabat: 47.8
CG_IVCp: 28.6
Tepe_Abdul_Hosein_N: 20.2
Levant_Megiddo_IBA: 3
Ethiopian_Ari: 0.4
Abdul Hosein + IVCp = These samples which are associated with Kulli and Sukaten Dor, people with closer to 80-85% Iran_N, beyond what is present in 8726
• 432, IPV Grave 109 (I11488): Context date of 3200-2100 BCE. Genetically female...
related to Baluchistan or to the
Makran coast and an alabaster bead.
But look some Iranian Baloch prefer 8726, your not going to find any Gujratis or any Indian population which has this as an IVCp source because most modern Indians have a shit tonne of tribal Pulliyar or Mala like ancestry. Take your meds so you don't become a bigger Bullshit artist.
sample: Iranian:9AQ101
distance: 1.965188048
Shahr_I_Sokhta_BA2_8726: 46
IA_Rabat: 38.4
Levant_Megiddo_MLBA: 14.8
Roopkund_A: 0.8
Even Steppe rich "Ror" need some SI AASI rich population with 48-50% AASI/Onge like ancestry, no surprise hundreds of millions of Indians are still like that and many with even more, it must be news to you.
sample: Ror:Average
distance: 0.712314874
Tamil_GBR: 36.6
Srubnaya_Alakul_MLBA: 34.6
Gonur1_BA: 21.8
Mereke_MBA: 5.2
Shahr_I_Sokhta_BA2: 1.8
@smellycaviar
You are too stupid to realize that what you are suggesting (minimally onge shifted I8726, btw I8726 only has 11-14% Onge) for Baloch, is nothing but a drifted form of IranN/WezmehN/AbdulHoseinN ancestry. Furthermore, the nonshared drift with Wezmeh_N is clearly not that high since the G25 distances for Baloch models with Wezmeh_N are low.
Such a population that you suggest has already been sampled from eastern Iran (shahr_sokhta). SiS is NOT selected for Makrani/Baloch, but Wezmeh_N is. This is because the Anatolian component in SiS is probably too high.
Whatever else you want to prove, prove it with rotating qpAdm models. G25 agrees with me, not you.
(scaled averages, 4x on vahaduo)
Target: Makrani
Distance: 2.1463% / 0.02146326
45.8 IRN_Wezmeh_N
19.0 RUS_Sintashta_MLBA
12.2 IRN_Shahr_I_Sokhta_BA2
12.2 Levant_Megiddo_IBA
7.6 PAK_Saidu_Sharif_H_o
1.4 RUS_Sintashta_MLBA_o3
1.2 PAK_Loebanr_IA_o
0.6 KAZ_Otyrar_Antiquity_o1
0.0 IRN_Shahr_I_Sokhta_BA1
0.0 KAZ_Otyrar_Antiquity
0.0 Levant_Megiddo_IA
0.0 Levant_Megiddo_MLBA
0.0 Levant_Megiddo_MLBA_o1
0.0 Levant_Megiddo_MLBA_o2
0.0 PAK_Loebanr_IA
0.0 PAK_Saidu_Sharif_H
0.0 RUS_Sintashta_MLBA_o1
0.0 RUS_Sintashta_MLBA_o2
Target: Brahui
Distance: 1.6964% / 0.01696353
33.4 IRN_Wezmeh_N
28.6 IRN_Shahr_I_Sokhta_BA2
17.8 RUS_Sintashta_MLBA
10.0 PAK_Loebanr_IA_o
8.0 Levant_Megiddo_IBA
2.2 KAZ_Otyrar_Antiquity_o1
0.0 IRN_Shahr_I_Sokhta_BA1
0.0 KAZ_Otyrar_Antiquity
0.0 Levant_Megiddo_IA
0.0 Levant_Megiddo_MLBA
0.0 Levant_Megiddo_MLBA_o1
0.0 Levant_Megiddo_MLBA_o2
0.0 PAK_Loebanr_IA
0.0 PAK_Saidu_Sharif_H
0.0 PAK_Saidu_Sharif_H_o
0.0 RUS_Sintashta_MLBA_o1
0.0 RUS_Sintashta_MLBA_o2
0.0 RUS_Sintashta_MLBA_o3
Target: Balochi_A
Distance: 2.1022% / 0.02102175
37.0 IRN_Wezmeh_N
20.8 IRN_Shahr_I_Sokhta_BA2
18.2 RUS_Sintashta_MLBA
14.0 PAK_Loebanr_IA_o
8.2 Levant_Megiddo_IBA
1.6 KAZ_Otyrar_Antiquity_o1
0.2 KAZ_Otyrar_Antiquity
0.0 IRN_Shahr_I_Sokhta_BA1
0.0 Levant_Megiddo_IA
0.0 Levant_Megiddo_MLBA
0.0 Levant_Megiddo_MLBA_o1
0.0 Levant_Megiddo_MLBA_o2
0.0 PAK_Loebanr_IA
0.0 PAK_Saidu_Sharif_H
0.0 PAK_Saidu_Sharif_H_o
0.0 RUS_Sintashta_MLBA_o1
0.0 RUS_Sintashta_MLBA_o2
0.0 RUS_Sintashta_MLBA_o3
I am planning on making a video responding to narasimhan’s genetics on steppe entry to India. However I am an amateur at genetics. Could I have a simplied explanation of your other articles, Vasishta?
1. Narasimhan's claim of special relation between steppe autosomal ancestry and modern Brahmins is weak - as proven by this article, and some other articles before.
2. Narasimhan's claim of female mediated steppe ancestry in Swat samples is correct, but the claim of male mediated steppe ancestry in modern Indians is wrong. I prove this in my previous article 'R1a explained'. The India specific R1a-L657 which is 70% of all Indian R1a, was born in India itself. In contrast, the steppe specific R1a-Z2124 is present in only ~5% of Indians.
3. Narasimhan's claim of no Iron Age steppe ancestry in modern Indians is also false. He claims that Iron age steppe has significant east Asian ancestry which cannot be detected in modern Indians. However that assertion is wrong - there are multiple samples from SC Asia which dont have any detectable east Asian ancestry such as 1100bce Kashkarchi samples from Uzbekistan or 850bce Turkmenistan_IA samples which are viable late sources of steppe ancestry for Indians.
Furthermore, some post iron age samples like Kangju (300bce) have low levels of east asian ancestry but are actually better sources of ancestry for many Indian groups. It is likely that a lot of steppe ancestry in modern Indians came later and was unrelated to the Vedic period.
Another claim made by Harvard in Shinde et al 2019 (Rakhigarhi sample) is that there is no Anatolian ancestry in IVC. That is also false (Maier et al 2022 preprint and my previous articles on Rakhigarhi and IVC models). That conclusion seems to be custom made to deny a trans iranian ancestry route for IVC folks.
@BlueCavier,
Your so stupid go FO back to Davidski's blog you 'mainstreamers' are so stupid you dont know anything and now this whole field is shit and boring I cant even be bothered to read Eurogenes boring comment section anymore.
You are such an ignoramous, there are levels to knowledge and you guys are such imbeciles and your theories so utterly retarded and nonsensical it cannot even garner a modicum of interest in the wider world let alone any interesting discussion.
Vasitha wrote,
"To conclude, modern data from various groups of the Indian subcontinent do not provide sufficient evidence to prove which ancestry (IVC or steppe) is responsible for Indo-Aryan languages."
Which means more ancient samples from the region are needed. You made a very insightful comment on the podcast with Sagorika that genetics can only disprove a linguistic theory not prove it. So till then both AIT (AMT) and OIT stand disproved. Correct.
Blue Calvalier,
"Stick to scamming elderly Americans"
You are the one bringing up the race card. Use your full name including your father's name if you want to talk to me. Ask mama; she may remeber it or do your qdpm analysis to find some good candidates from the admixture data. My next post is going to be even more abusive.
Mayuresh Madhav Kelkar
This was a video I made a while ago. I showed it on the World of Antiquity channel but the premise was struck down on the fact that I didn’t account for ancient DNA. Would you review it Vasishta and see what I must add?
Link to video?
Sorry, here is the link: https://youtu.be/w7VWOLMheOs
Akshai has written a nice post on the false claims that have been made so far which relate the steppe bronze age archaeology to Indo Aryans.
https://pradyaus.wordpress.com/2022/11/16/a-review-of-the-kurgan-hypothesis-pertaining-to-the-aryan-expansion-into-india/
I would love to make another video, this time responding Narasimhan et Al. However I don’t know how to format it so a layman could understand it.
I am aware that 1650 bce for steppe dna is late and the narrow time frame is irrelevant. I am aware that the swat valley sample is the the wrong z93
But I am not sure how to proceed from there.
@Anon
Please use a proper handle name, it helps others to pinpoint who they're talking to.
I saw the video, overall an admirable effort.
1. I disagree with the premise that R1a is the sole marker of Indo-Aryans. That might be true of some parts of Europe, doesn't make it accurate for India. Lazaridis et al 2022 note that the 'southern arc' was the PIE homeland, that region has no R1a. As we all should know by now, Y haplogroups don't encode for the language spoken. This is why Baltic-speaking Latvia and Lithuania have 35% Y hg N but don't speak the Finnic language. Basques have 80+% R1b-M269+ but still don't speak IE. R1a-Z93 > Steppe Z2124 is now most frequent in Turkic speakers (Kyrgyz for eg).
2. Your assessment of older R1a-Y3 presence in India is correct. R1a-Y3 (born ~2600BCE) and L657 (born 2200bce) are purely Indian-subcontinent specific, and therefore must have been born in India itself. Given that they're born to just 1 man, as opposed to an invasion of many Y3 or L657 men, it is unlikely that this is associated with language change. This blog post of mine explains it in detail.
https://a-genetics.blogspot.com/2022/10/r1a-explained.html
3. You are a bit mistaken when you explain the date of the Swat Pakistan samples. Even though the date of the samples is 1200-900bce, the 15% steppe admixture in them is said to be from around 1700-1600bce (DATES analysis by Narasimhan et al 2019). I don't trust the software DATES much, but it is what it is. There is also one outlier sample from Bustan which shows a Swat IA profile and is dated to 1550bce. However, this does not prove that steppe autosomal ancestry entered mainland India at the same time. There is yet no proof of that, genetic or archaeological.
4. From what I see in models of modern Indians, a lot of steppe ancestry came from sources like Turkmenistan_IA (850bce) or Kangju (200CE) which have additional BMAC and/or some east Asian ancestry. If such a late entry of steppe ancestry in Indians is proven by actual samples, then the steppe theory is busted.
5. A mere entry of steppe ancestry is not a sufficient level of evidence to prove that it changed the language of the whole northern half of the subcontinent (especially without any archaeological proof). The bulk of the ancestry in Indians is still associated with the Iranian Neolithic, which itself is linked to PIE by Lazaridis et al, that route is still very much viable (Heggarty note pst the 'southern arc' paper)
6. There is no shred of sintashta-related ancestry near Iraq, western Iran and Syria around 1800-1500bce when Kassites and Mitanni invoke Vedic Gods. (even till 700bce). Refer to my featured 'Southern Arc' post.
7. Finally, the falsities proposed by the likes of Kuzmina, Anthony, Witzel, Parpola etc who sought to link Sintashta with Aryans by hook or by crook must be exposed, often by torturing RV verses to their limit and making them mean what they don't mean. Akshai has written a nice article about this.
https://pradyaus.wordpress.com/2022/11/16/a-review-of-the-kurgan-hypothesis-pertaining-to-the-aryan-expansion-into-india/
I had written another article about that topic
https://a-genetics.blogspot.com/2021/12/potapovka-horsehead-hoax.html
When your critics say 'it does not account for ancient dna', as long as you have accounted for the Swat findings you have accounted for ancient DNA, as that is the only published ancient DNA from the Indian Subcontinent (apart from a single low-quality sample from Rakhigarhi)
I mentioned all of Narasimhan et al's weak points in a previous reply.
The main weak point is his false claim that R1a in modern Indians is mediated by steppe males. I debunk that in my 'R1a explained' post.
@vAsiSTha I would love to cite you, but in case anyone asks, do you have qualifications in genetics?
"do you have qualifications in genetics" I dont
@ vAsiStha One more thing, what made you conclude the date for steppe admixture to be narrowed down to 1700-1600 bc.
My ethic group, from Gujarat, is furthest genetically from other South Asians and also most eurasian populations compared to other Indo Aryans and South Asians.
In 23andme I can see lots of people from my group and we have mostly J y-dna, some R1A and R1B. I have J-P58 and others mostly had other clades of J1 and J2.
Jatts are closest to me genetically according to fstats. This also makes sense because we have a strong farmer identity just like the Jatts. According to 23andme we have upto 10% West Asian admixture, but I know this is not correct. With fstats I can see all other Indo Aryans are closer to Iranians than me. The 10% West Asian is just alleles we share with West Asians but not with other South Asians.
I also am closer to more ancient West Eurasian pops compared to other Indo-Aryans, Rors particularly, who are more closer to later West Eurasians especially Steppe and more recent peoples.
What I think happened, is that in that at some point in the past, NW South Asia had more J and related Y-DNA. From there populations expanded to Iran and other places maybe even the Steppe. Later on and with time R1A became more dominant in that region, by which point many of the earlier J1 lineages may have become farmers and the R1A were the vedic nomads.
Then this 'newer' nomadic pop, reflected best with the Rors, continued to expand from this NW region both into India, West Asia and also Steppe.
My ethnic group has the least amount of admixture from this newer NW (Vedic?) group, hence we have more ancient eurasian Y-DNA. Note that J lineages will be historically and anciently more distant genetically (autosomally) to most other Eurasians. R1A lineages are most Central.
SO the J lineages would have expanded from India a long time ago and then this homeland region became dominated by R1 and then that lineage expanded. Or the J lineages may have just been farmers while R1 Nomadic. Vedic and IE is generally considered nomadic. But then the J lineages are closely assocatiated with IE too. So its more likely that J1 and older lineages were more reflected in the earlier IE nomadic peoples in South Asia, over time they became farmers, then R1A expanded out later.
@mzp1
No offense, that is not in line with genetic studies.
What ethnic/caste group from Gujarat are you?
I have not seen any sample from Gujarat who are close to Rors or Jatts so far. I have yet to come across such sample from Gujarat.
Most West Eurasian shifted South Asians are Balochi (more than Kalash or Ror), there is no way some ethnic group from Gujarat are similar to such population unless they are recent migrants. West Eurasian ancestry declines east of Indus river (that includes Gujarat and Punjab) as East Eurasian cline picks up more with AASI shift.
@ vAsiStha One more thing, what made you conclude the date for steppe admixture to be narrowed down to 1700-1600 bc.
Two things
1. The 1550bce bustan outlier which shows swat iron age like ancestry. The hypothesis being that if we had such an old sample from swat it would also show steppe ancestry
2. Multiple DATES output which show that admixture between steppe and AASI in the swat samples occurred ~700 yrs prior to the dates of the samples (from Narasimhan et al which matches with my dates analysis).
If I'm not wrong, MZP is bohra muslim which means that he likely has some additional baloch like ancestry.
New Harvard dataset v54 is out.
@Vasist
"If I'm not wrong, MZP is bohra muslim which means that he likely has some additional baloch like ancestry."
That makes sense, especially since they are Shia.
South Asians on 23andme don't show West Asian admixture unless it's recent ancestry.
@vAsiSTha Could you show me the reference for Swat Valley samples being R1a Z2142?
None of the 2 swat valley Iron age R1a samples are Z2124. Theyre just Z94. I dont recall if the later buddhist period samples were Z2124, but theyre not L657 for sure.
In the much later medieval Ghaznavid samples from 1000 ce or so, 2 are Z2124.
Im Bharuchi Vohra, we are not really similar to Dawoodi Bohras, they are city ppl, traders with recent West Asian influences. We are farmers around Bharuch and have quite a different culture to them.
I checked it all out completely, fstats, 23andme, HarrappaProject etc I have been looking at this for years. We have no genetic recent ancestry from West Asia as ALL other Indo Aryans are closer to them. Rors are also closer to ONG using fsats but in other calcs I can get a bit higher ASI due to just being more distant from ancient (but recent) west eurasians.
Heres my HarrappaWorld thing.
https://ibb.co/LpCSrYk
I am closest to Jatts and Kashmiris according to HarrappaDNA. I am not sure that really reflects reality though and it could be a problem with the model they have because in fstats I am close to Jatts but not Kashmiri Pandits. Although phenotypically my group is quite close to Kashmiris with a bit of variation either way.
The only thing that makes sense is that I tend to be closer to older Eurasians than newer ones compared to other Indo Aryans but most with Rors. Rors are also very central and genetically close to all Indo Aryans and recent West Eurasians. So they could be quite close to the most recent IE expansion point. There is place in Sindh called Rorhi which has a lot of history that seems to relate to Ror. That is a good location for an ancient IE nomadic culture that could travel to lots of other places inc East but also North and West.
I tend to show alot of affinity to West Eurasians genetically but these models assume populations mixed in South Asia recently not expanded from there. Hence, the West Asian affinity I have is mostly just older DNA that expanded to West Asia earlier, maybe related to farming. Similarly, there is a community South of us that is also very similar but separate. I have seen one of there results and instead of the 5% West Asian I get they got some South Indian. So it looks like these models are just assuming the wrong direction flow in some cases.
For me to have J1 and all these other types of characteristics but it is just older genetic relations with less of recent expansion from within South Asia. That recent expansion connects South Asians mostly to Steppe DNA, so it looks like Nomadic to Nomadic contact and within South Asia those ppl are also becoming farmers over time.
The f4 shows I am further away from Saudis and Iranians than most Indo Aryans. Its only for Iberomaurusians that I am closer to anyone compared to GujaratiB.
https://ibb.co/HBMMxpm
@mzp1
You're scoring rather high SW Asian + Mediterranean and higher Caucasus as well. Scoring high combination of that together on HarrappaDNA is not common in South Asians though from what i've noticed.
Have you checked your "Ancestry Timeline" on 23andme? do they give you any admixture events? your 10% West Asian on 23andme will appear there with timeline of admixture event
When it comes to ancient DNA, J1 appears to be Caucasus-related haplogroup so far, we can't say much other than that.
I suggest getting your G25 coordinates and test it out further
@Vasist
Have you looked at this new ancient study from Upper Mesopotamia yet?
A genomic snapshot of demographic and cultural dynamism in Upper Mesopotamia during the Neolithic Transition
https://www.science.org/doi/10.1126/sciadv.abo3609
J1 is most common in Arabs, near east and Iranians
"Have you looked at this new ancient study from Upper Mesopotamia yet?"
Yes, but I found nothing out of the ordinary there.
@Vasistha
J1 is most common in Arabs, near east and Iranians
Currently, there is a lot of J1 from ancient DNA from Caucasus-steppe-Iran region, it's also in one of the Mesolithic EHG from Karelia in far north, and it's also in eneolithic steppe like Khvalynsk.
It looks to be associated with CHG based on that. If not then maybe earlier paleolithic Caucasus population like Dzudzuana.
In that new 'Upper Mesopotamia during the Neolithic Transition' study there wasn't any J1 oddly enough.
What you say about J1, chg and steppe is true, but if you look at modern distribution, J2 is present in significant amounts in European countries (often 15-20%, check tableau dashboard of yfull samples). J1 is not that frequent.
I should probably study subclades of J2 and their spread.
J1 in Mesolithic EHG is most likely related to paleolithic Dzudzuana-related ancestry since Lazaridi in Southern Arc study says admixture between EHG and CHG only took place during 5000 BCE forming Eneolithic steppe groups, and later around 3000 BCE some kind of southern arc ancestry contributes to Eneolithic steppe. Yamnaya emerge from this admixture.
"Determining the proximate source of the two movements into the steppe from the
south will depend on further sampling across the Anatolia-Caucasus-Mesopotamia-Zagros area
where populations with variations of the three components existed. Similarly, on the steppe side,study of Eneolithic (pre-Yamnaya) individuals could disclose the source dynamics of Caucasus hunter-gatherer infiltration northward and identify the likely geographical region for the emergence of the distinctive Yamnaya cluster, which we show has an autosomal signal of admixture dating to the mid-5th millennium BCE [fig. S5 and (19)], coinciding with the direct evidence of the first southern influence provided by the Eneolithic individuals of the steppe."
I thought maybe new Upper Mesopotamia study could be helpful in finding that ancestry. There is J2 in one of the samples from that study, I don't know what kind it is though.
When I do the calcs to see what other pops I am closer too, I have to use Rors (or maybe Gujaratis) as outgroups, and maybe steppe DNA. Its just because we know Ror as generally close to Steppe, and I know Steppe are the outside pop closest to South Asians.
Ror is also close to most other outside pops so I can use Ror as an outgroup.
https://ibb.co/HHQFznL
This f4 shows I have the greatest affinity to Karelia HG vs Samara HG and Rors. Karelia is J1, and Samara R1A I think, so it is possible there is a small detectable autosomnal closeness between me and Karelia hence Karelia also has J1.
I have looked at lots of pops now. It seems I have some extra closeness to TepeHissar and other farming or agricultural peoples outside India, it seems to be going through Balochistan, Iran, Caucases, and then possible early Euros like HG or LBK maybe.
It looks a lot like H and J2, in terms of going Iran, Caucauses, Europe but not North through Steppe, which is more related to R1.
https://upload.wikimedia.org/wikipedia/commons/c/c1/Y_haplo_H.pnghttp
I think the best way to see it is like this.
https://ibb.co/VjNYM8F
That is whether a population is closer to me or Ror vs each other. It is the mean for W in the calc f4(pop, pop, me, Ror).
The top one is closest to Ror vs the others and the bottom one closest to me.
As you can it basically has the Farmer type people closest to me, and EHG and Steppe is closest to Ror.
If I run the same calcs with Balochi or Gujarati vs Ror it is not the same.
https://ibb.co/yNvxTS3
Gujarati vs Ror
https://ibb.co/0V782Mm
Balochi vs Ror
https://ibb.co/30R3d2y
Kalash vs Ror
For me the trend is the clearest, farmer cultures are closer to me and EHG/Steppe is closer to Ror.
So most likely there South Asian farmer geneflow going into West Eurasia probably from around Baluchistan (Mehrgarh?) and then into Iran and then possible NW from there (J lineages). There is also Nomadic (Vedic?) geneflow from South Asia into Steppe which seems to tie Rors and Sidelkino/Steppe EBA closer together (R1 lineages).
Wow...
This one is really interesting..
I ran the same calcs but with me vs GujaratiB. Gujaratis are very similar to Rors when compared with others, they are just more Southern and have wider and more ancient genetic affinities.
https://ibb.co/WVMvB6R
The bottom ones closest to me: Tryphilia, LBK, Hissar all the ancient farming civilizations omg !!!
So what do you guys think? I'll probably write this all up on my blog at some point.
In summary. I have the lowest amount of Steppe DNA ie NE Euro in HarrappaDNA. This is because Steppe DNA consists of lots of South Asian DNA which is coming from the most recent dispersal point in NW South Asia. These people are closer to Rors and Gujaratis but Jatt, Pathan, Balochi and Kalash also have a lot and sometime more than Ror. I have the least amount of recent DNA contact with other groups esp mainstream Indo Aryans and from the dispersal point, hence I am furthest away from other neighbouring ppl by a big amount.
But I have a lot of very ancient DNA from around the NW dispersal point hence I am relatively close to ancient NW Eurasians like Iberomaurusians, Yoruba, Kostenki, Ust Ishim etc.
This makes alot of sense to me: Tribal > Nomadic > Farmers is the process that people are going through. We went through this process in South Asia and became Nomadic (IE) and then farmers before anyone else whos DNA sample we have.
At this point we are no longer migrating to the Steppe but if my ancestors left India they probably followed the farming routes through Iran and into West Asia, hence I get alot of affinity to the farmers and also the 'Southern' input into Steppe which we see with Afanasievo, SIntashta and others.
From South Asia the ppl most likely to migrate North into the Steppe were the Nomadic ppl at the time which is best represented by Ror.
All the mountainous terrain in Central and West Asia had lots of these farmer type DNA. Possibly these farmers are crossing over the mountains and every so often leaving to go North into Steppe or Europe and joining the nomads. This is the source of the Southern Ancestry in Steppe.
So Steppe DNA has 2 sources of ancestry. One is closest to Ror and Gujarati coming from the Nomads of Sindh and the Indus region, the other is moving out from farming settlements in the mountains around Southern and West Asia and joining into the Steppe groups. This is bringing something more like Jatt, Pathan, Kalash and especially my own group as I score higher than the others for this.
The people who are more diverged from Gujarati and Ror, and further from India tribals, like Jatt, Kalash, Pathan and myself, we would of been in the NW dispersal point much earlier, but left, my ppl went south to Gujarat, Jatts went East into Punjab, Kalash went North and Pathan West. Some left earlier than others and hence are further from Ror and Gujarati. I am the furthest.
Its very Eurocentric and incorrect to associate Steppe and R1 lineages specifically with IE and give them some special status. J lineages and others are connected to IE but older, and more developed and advanced.
J1 - R1A - R1B
J1 is more often found with R1A not R1B. Even Jews have J1 and R1A.
None of this needs to be due to mixing. J1 and R1 were in close contact in NW South Asia. R1 is frequent in Indian tribals, I dont know about J. J1 and R1 is the most influential expansion of IEs.
Semitic is not IE but its not hard to imagine that these ppl were once IE speakers but they left the homeland a very long time ago, or became farmers very early, so their language diverged from IE and became unrecognisable. But Semitic still has a few IE words that could be recent borrowings or since ancient times.
When ppl become farmers, esp in South Asia, their language and genetics, compared to the Nomads diversifies really fast. Its because farmers dont need to mix and communicate and trade with others in the same way so everything starts to change. Even the religion. Hence with Semitic ppls they have very little similarity to IE, its just because they left so long ago they have drifted a lot.
Steppe EBA is like the poorest most un-influential and least prestigious of all groups around that time. They are lower in socioecomic status and everything, to label them as PIE and super game changers is kinda stupid.
Also, the Steppe groups only really become important archeaologically after developments by farmers. In Europe this is with EEF and Steppe EBA only appears in the archeological record after the development of the Eneolithic and Civilizations like BMAC, Maykop and IVC.
Its always the farmers who are bringing the change. By the BA the farmers are well superior to the Nomads. This is not even close.
Both the Farmers and Nomads originate in South Asia. The farmers are the older nomads and hence share older DNA with the rest of Eurasia. My group is the oldest group hence it has a different autosomnal profile compared to other South Asians esp when compared to West and North Eurasians. I have a lot less Steppe DNA and more Farmer type stuff which can look like Anatolian, Mediterreanian, Iranian, Caucasian etc. Because DNA is expanding from South Asia I get more of the older more distant 'components' like Mediterreanian, Caucasian, SW Asian and less of the newer (and less diverged) component NE Euro.
As a policy, I do not make conclusions for pre historic population movements based on some individual's DNA or y haplogroup.
Yeah makes sense..
But I think the biggest smoking gun for OIT is the Y-DNA of South Asians esp tribals and those IAs with higher 'ASI'. These are on the tribal and ASI (E and S) side of Gujaratis, while most IEs are on the NW side of Gujaratis.
Tribal Indians and higher ASI groups have most of the Y-DNA distribution of Eurasia. All the way from C-R inc all the J and R stuff.
So I dunno I think OIT is pretty obvious I dunno I was reading Wikipedia about IJ they kept talking about Caucuses and West Asia but Indians today do have I and J. You can see from here Indians have all the Y-DNA distribution of Eurasia so literally every HG has a significant presence in India so very of these can be defined as West Asian, European or whatever inc J and R1A.
https://en.wikipedia.org/wiki/Y-DNA_haplogroups_in_populations_of_South_Asia#
I is definitely linked to european WHG
@Vasist
There are 60 to 70 Rakhigarhi samples available on Ebi site. One of them was analyzed by theytree.
https://www.ebi.ac.uk/ena/browser/view/PRJEB34154
"people in the net were able to anlaysed 1 male individual named I2487 out of these 61 remains ( from good enough quality) to the level of e-pf1962 ... in the bam files link above from ENA site The individual I2487 is named S2487"
His haplogroup e-pf1962 is same as some found in Swat Valley Udegram_SPGT and Gonur BMAC
https://www.yfull.com/tree/E-M34/
Can you analyze rest of these samples even if they are of low coverage maybe it is possible to determine their haplogroups till upstream levels at least?
Interesting. If true, that signifies an Akkadian connection.
There are replicate libraries on only 2 individuals uploaded in that accession number. 1 is the already published woman from Rakhigarhi. The other is S2487 but Niraj says no y haplo was assigned due to low coverage.
mzp1 wrote,
"Its very Eurocentric and incorrect to associate Steppe and R1 lineages specifically with IE and give them some special status. J lineages and others are connected to IE but older, and more developed and advanced."
As you may recall from that Igor TB paper, IIr havw a a lot in common with Greek and Armenian branches, than the other branches currently found in Europe.
https://brilliantmaps.com/europe-dna-borders/
Given that Greeks have J2, and if haplogroups have anything do with language, Greek and Armenian may not have been spread by nomads at all. Slow diffusion will work.
Recent Podcast with Professor Nicholas Kazanas,
https://www.youtube.com/watch?v=nCPE2jIdYIE
Is this guy making any sense?
https://youtu.be/GH7er7ak7K4?t=23
Any references for Kazanas' claim of archaeological introgression post 600bce?
Hey ashish. Malik doesn't mean muslim jatt, those malik sample are of hindu jats. Malik is title of gathwala and lall jats. It is one of biggest clan of hindu jat in northern western uttar pradesh and eastern haryana. The sample you have marked as muslim jatt are of hindu malik jatt
What is your community name
"More enlightening factor will be sintashta+bmac/sintastha+bmac+IVC ratio in which Up/bihar brahmin were top" lol. Narsimhan have not taken haryana jat,ror sample and he have marked some dalit sikh using jatt surname as jatt sikh sample! There is no way brahmin have higher steppe+bmac than jats.
"Malik doesn't mean muslim jatt, those malik sample are of hindu jats. Malik is title of gathwala and lall jats."
I know Maliks are Hindus. But these coordinates have not been coordinated by me, but someone collated them from submitted coordinates of private users on Anthrogenica etc. So in this case these might be coords from someone whose family has converted.
There is not even a single sample of muslim jatt of Uttar pradesh as far as I know. Malik sample you have taken is the individual I know personally his name is ajay singh malik, his wife is Pacchada(punjabi) jatt whose sample is with name bassi Pacchada jatt.
Male- Hindu jat-malik (gathwala)
Y-haplo-L-M357
16 ancestral populations
188173 total SNPs
14 flipped SNPs
18715 heterozygous SNPs
85 no-calls
135443 absent SNPs
0.279769 genotype rate
mode genomewide
135528 SNPs missing (no-call or absent)
7840 dQ: 1.002E-07 goal: 1.000E-07
7847 total iterations
9.999E-08 final dQ
----------------------------
FINAL ADMIXTURE PROPORTIONS:
----------------------------
26.33% S-Indian
34.20% Baloch
14.05% Caucasian
20.30% NE-Euro
0.38% SE-Asian
0.78% Siberian
0.00% NE-Asian
0.02% Papuan
2.83% American
0.13% Beringian
0.70% Mediterranean
Ok, since you are sure I removed Muslim from the label.
Do Gujarati Patels and UP/Bihar kurmis have any genetic similarity with each other?
Can't say. I havent seen Kurmi data.
Is there any chance that the civilizations in Gangetic valley like those in Lahuradewa and Chirand had a majority of their ancestry coming from the Iranian hunter gatherers like those in the IVC?
"Is there any chance that the civilizations in Gangetic valley like those in Lahuradewa and Chirand had a majority of their ancestry coming from the Iranian hunter gatherers like those in the IVC?"
Maybe, its not crazy to think of such a possibility.
@blue caviar Go back to eurogenes or 4chan and cry about it there,or take a hold of your tongue and what you are saying.
You seem to be triggered like a leftist because the sintashta invasion Ancestry has been disproven so you can't claim Vedas and indo aryan as yours now and you also can't celebrate the Aryan invasion now(something which never happened) which you Nazis do all the time on 4chan.
Don't try to act An oversmart I-know-it-all.
Your God davidski is coping since his bullshi/ is getting disproven everyday,even the majnstream is shifting from his shi//y theories
There are many people who claim that Kammas and Gujarati Patels have common origin. Is this possible?
"There are many people who claim that Kammas and Gujarati Patels have common origin. Is this possible?"
Idk about Patels, but Kamma could have Gujarati origin. IBD analysis might throw more light.
Velirs are said to be descendants of Krishna from Dwarka as per 200 BCE Sangam texts. Any Andhra connection with Velir? Maybe Velamas are also Velir idk.
Tamil Velallar are those Velirs mentioned in Sangam texts.
Vellalars are also farmers. They seem to have higher iran n compared to others.
Gujarati Patels though do not have a strong farmer identity though afaik. Patel means Farmer ie Patidar Land-Holder. Most Gujarati Patels.come from cities like Surat so I am not sure how they inherited the title Patel.
Gujarati Patels are probably just more Southern genetically than GujaratiA and GujaratiB from the Reich Dataset. Northern Gujaratis like GujaratiA and B are closer to Sindis and NW Indo Aryans and will have greater affinity to NW Eurasians than Patels.
Within Gujarati there is a South to North cline where south is closer to Asi and tribals and north is closer to NW Eurasian.
Patel is just a title and various groups have adopted it. In the same way I dont think Gujaratis have any special relation to any other place or group inc Kurmis or Kammas. This associations may be more political or later adoptions like the Patel identity which many different groups in Gujarat share.
Because Gujaratis are very central in their closeness to other pops within and outside of India it is unlikely they have a special relationship to any group. They are closer to evryone on average compared to anyone else.
Gujarati is where Indian cattle would of lived and should be the point of domestication. Those cattle would have been herded up the Indus rivers and that cow herding economy which starts from Gujarat and goes North and then NWE is the begining of the Indo Europeans.
Afaik evryone in India was tribal HGs.
Then ppl started domesticating cattle in Gujarat. Then dogs and horses came later as they made cow herding easier.
They took the cows further north along with their Gujarati genes. Further drift in NW leads to differentiating from Gujaratis to North Indian phenotype and genotype.
But Gujarat is the source of the populations that would.move North into NW and create the Indo.European.culture.
Cow herders from Gujarat can only go North afaik not South so that is why IE is mostly North from Gujarat all the way to NW Eurasia.
The region.from Gujarat to KPK were all IEs but not UP. UP indo Aryans.came from the West from anywhere between Gujarat and KPK.
Even if you look at the most and least steppe.shifted Swat samples the difference is better explained by DNA from Gujarat rather than Steppe.
So there is genetic expansion of populations from Gujarat-Indus Region into other parts of India but ppl are misinterpreting this as Steppe Dna introgression.
Reading mzp bro's comment makes me realize how there are no lack of regional ethno-centrists who consider their group or region as the harbinger of pretty much everything :).
@mzp, a few questions -
"But Gujarat is the source of the populations that would move North into NW and create the Indo European culture.
Even if you look at the most and least steppe shifted Swat samples the difference is better explained by DNA from Gujarat rather than Steppe
"
Where is the aDNA from Gujarat for such modeling ? Are you solely saying that on the basis of affinity towards some modern groups of Gujarat in f4stats ?
"Gujarati Patels though do not have a strong farmer identity though afaik. Most Gujarati Patels come from cities like Surat so I am not sure how they inherited the title Patel."
I think not all have transitioned to the mercantile role and there's decent section of them engaged in farming. Combining all their sub-castes, they form the largest caste of Gujarat IMO, around ~15% if I am not wrong. As for Surat, I think those would be Leva Patidars right ? Don't the Kadava patidars come from further up north ?
Regarding origin and dispersal of your Y-HG J1 from Gujrat, Why do you think that's the case ? The argument that an ancient farming population from Gujarat brought Y-HG J1 to Iran, Middle East and West Asia doesn't seem correct considering a pre-Holocene Hunter Gatherer from Caucasus region (CHG) was found to have Y-HG J1.
It seems that the Indus high AASI has very small amount of Anatolian Hunter gatherer ancestry as compared to the Indus low AASI.
@mzp1 this cell attachment shows that there is a lot of derived allele sharing between the gujarati samples and the kurmi population.
https://www.cell.com/cms/10.1016/j.ajhg.2018.10.022/attachment/711bfd84-99c1-44e6-8b40-fbde264460f6/mmc1
Post a Comment